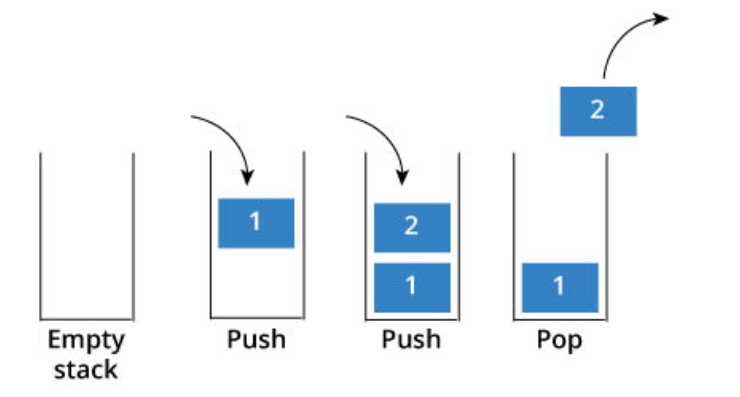
栈(stack)定义与实例 栈(stack)定义: 距离栈底越近的数据项, 留在栈中的时间就越长而最新加入栈的数据项会被最先移除,这种次序通常称为“后进先出LIFO”:Last in First out这是一种基于数据项保存时间的次序,时间越短的离栈顶越近,而时间越长的离栈底越近.
抽象数据类型Stack:操作样例
Stack Operation
Stack Contents
Return Value
s= Stack()
[]
Stack object
s.isEmpty()
[]
True
s.push(4)
[4]
s.push(‘dog’)
[4,’dog’]
s.peek()
[4,’dog’]
‘dog’
s.push(True)
[4,’dog’,True]
s.size()
[4,’dog’,True]
3
s.isEmpty()
[4,’dog’,True]
False
s.push(8.4)
[4,’dog’,True,8.4]
s.pop()
[4,’dog’,True]
8.4
s.pop()
[4,’dog’]
True
s.size()
[4,’dog’]
2
Python的面向对象机制, 可以用来实现用户自定义类型 将ADT Stack实现为Python的一个Class,将ADT Stack的操作实现为Class的方法
可以将List的任意一端(index=0或者-1)设置为栈顶,我们选用List的末端(index=-1)作为栈顶,这样栈的操作就可以通过对list的append和pop来实现:
不同的实现方案保持了ADT接口的稳定性但性能有所不同,栈顶首端的版本(左),其push/pop的复杂度为O(n),而栈顶尾端的实现(右),其push/pop的复杂度为O(1) .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Stack : def __init__ (self ): self.items = [] def isEmpty (self ): return self.items == [] def push (self, item ): self.items.append(item) def pop (self ): return self.items.pop() def peek (self ): return self.items[len(self.items)-1 ] def size (self ): return len(self.items)
下面看看如何构造括号匹配识别算法从左到右扫描括号串,最新打开的左括号,应该匹配最先遇到的右括号这样,第一个左括号(最早打开),就应该匹配最后一个右括号(最后遇到)这种次序反转的识别,正好符合栈的特性 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def parChecker (symbolString ): s = Stack() balanced = True index = 0 while index < len(symbolString) and balanced: symbol = symbolString[index] if symbol == "(" : s.push(symbol) else : if s.isEmpty(): balanced = False else : s.pop() index = index + 1 if balanced and s.isEmpty(): return True else : return False print(parChecker('((()))' )) print(parChecker('(()' )) def parChecker (symbolString ): s = Stack() balanced = True index = 0 while index < len(symbolString) and balanced: symbol = symbolString[index] if symbol in "([{" : s.push(symbol) else : if s.isEmpty(): balanced = False else : top = s.pop() if not matches(top,symbol): balanced = False index = index + 1 if balanced and s.isEmpty(): return True else : return False def matches (open,close ): opens = "([{" closers = ")]}" return opens.index(open) == closers.index(close) print(parChecker('{{([][])}()}' )) print(parChecker('[{()]' ))
在实际的应用里, 我们会碰到更多种括号,如python中列表所用的方括号“[]”,字典所用的花括号“{}”
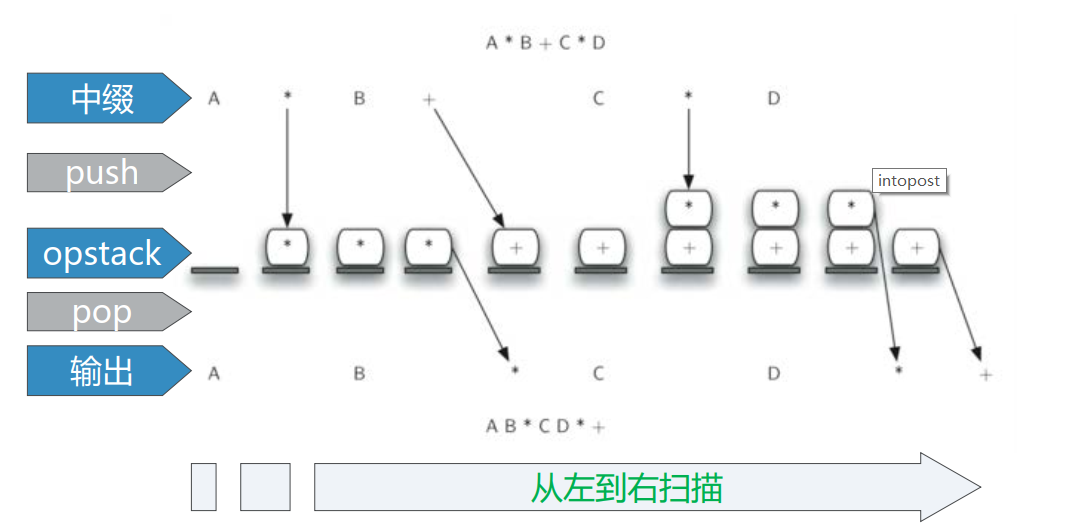
中缀转后缀算法 首先我们来看中缀表达式A+B*C , 其对应的后缀表达式是ABC*+ 操作数ABC 的顺序没有改变。操作符的出现顺序,在后缀表达式中反转了由于*的优先级比+高,所以后缀表达式中操作符的出现顺序与运算次序一致
从左到右扫描中缀表达式单词列表:
如果单词是操作数,则直接添加到后缀表达式列表的
如果单词是左括号“(”,则压入opstack栈顶
如果单词是右括号“)”,则反复弹出opstack栈顶操作符,加入到输出列表末尾,直到碰到左括号
但在压入之前,要比较其与栈顶操作符的优先级
如果栈顶的高于或等于它,就要反复弹出栈顶操作符,加入到输出列表末尾
直到栈顶的操作符优先级低于它
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def infixToPostfix (infixexpr ): prec = {} prec["*" ] = 3 prec["/" ] = 3 prec["+" ] = 2 prec["-" ] = 2 prec["(" ] = 1 opStack = Stack() postfixList = [] tokenList = infixexpr.split() for token in tokenList: if token in "ABCDEFGHIJKLMNOPQRSTUVWXYZ" or token in "0123456789" : postfixList.append(token) elif token == '(' : opStack.push(token) elif token == ')' : topToken = opStack.pop() while topToken != '(' : postfixList.append(topToken) topToken = opStack.pop() else : while (not opStack.isEmpty()) and \ (prec[opStack.peek()] >= prec[token]): postfixList.append(opStack.pop()) opStack.push(token) while not opStack.isEmpty(): postfixList.append(opStack.pop()) return " " .join(postfixList) print(infixToPostfix("A * B + C * D" )) print(infixToPostfix("( A + B ) * C - ( D - E ) * ( F + G )" ))
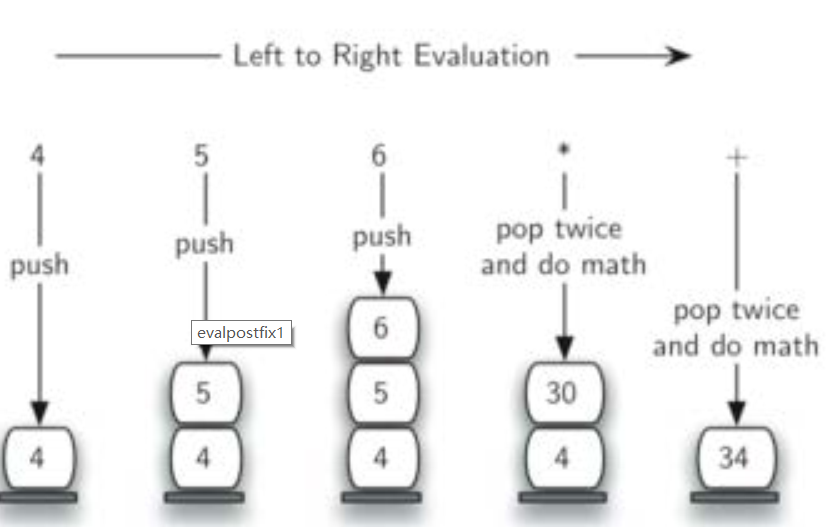
后缀表达式求值 如“4 5 6 +”, 我们先扫描到4、 5两个操作数,但还不知道对这两个操作数能做什么计算, 需要继续扫描后面的符号才能知道,继续扫描, 又碰到操作数6,还是不能知道如何计算, 继续暂存入栈,直到“ ”, 现在知道是栈顶两个操作数5、 6做乘法 ,弹出两个操作数, 计算得到结果30。需要注意:
先弹出的是右操作数,后弹出的是左操作数,这个对于-/ 很重要!
为了继续后续的计算, 需要把这个中间结果30压入栈顶
继续扫描后面的符号
当所有操作符都处理完毕, 栈中只留下1个操作数, 就是表达式的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ef postfixEval(postfixExpr): operandStack = Stack() tokenList = postfixExpr.split() for token in tokenList: if token in "0123456789" : operandStack.push(int(token)) else : operand2 = operandStack.pop() operand1 = operandStack.pop() result = doMath(token,operand1,operand2) operandStack.push(result) return operandStack.pop() def doMath (op, op1, op2 ): if op == "*" : return op1 * op2 elif op == "/" : return op1 / op2 elif op == "+" : return op1 + op2 else : return op1 - op2 print(postfixEval('7 8 + 3 2 + /' ))